수요산책
 > 인권연대세상읽기 > 수요산책
> 인권연대세상읽기 > 수요산책
‘수요산책’은 각계 전문가들로 구성된 칼럼 공간입니다.
‘수요산책’에는 박록삼(전 서울신문 논설위원), 박상경(인권연대 회원), 서보학(경희대학교 법학전문대학원 교수), 이윤(경찰관), 이재환(시흥시청 소상공인과 지역화폐팀 책임관), 조광제(철학아카데미 대표), 황문규(중부대학교 경찰행정학과 교수)님이 돌아가며 매주 한 차례씩 글을 씁니다.
인권에 빗대어 AI를 생각해 본다.(조광제)
작성자
hrights
작성일
2023-05-24 09:23
조회
218
조광제/철학아카데미 대표
최근 ChatGPT의 출시에 따른, 기계 지능에 의한 인간 권리의 추락 가능성이 예고되면서 논란이 분분하다. 평소 매체 철학에 관심을 두고 여러모로 생각해 온 바를 인권연대 구성원들과 공유하고자 한다. 철학을 전공하는 인문학자로서 AI를 중심으로 로봇공학에 전문적인 지식을 가질 수는 없다. 하지만, 관련 문헌들을 살핀 내용들을 기초로 해서 어쭙잖게나마 생각을 전하고자 한다.

출처 - decoder
- AI 불안
1) ChatGPT 4.0 아노미 현상
매체 환경이 심하게 요동치고 있다. ChatGPT 4.0 버전의 출시가 세간의 화두로 등장해 위력을 발휘하고 있다. 그동안 AI 부문에서 수십 년간 연구에 몰두해 온 전문가들이 최근에 이 프로그램을 시연해 본 후, 이른바 ‘멘붕’에 빠졌다고 한다. 일반인은 아직 그 정체를 제대로 알지 못한 채 인간 능력을 초과하는 어마어마한 능력을 발휘한다는 사실만 듣고 시연해서 놀라면서 동시에 불안해한다. AI 연구 개발의 역사에서 ChatGPT 4.0이 얼마나 어떻게 충격적인가를 실감하지 못한다. 이 정도로 막강한 AI를 만들어 내는 일이 얼마나 어려운가를 잘 모르기 때문이다.
우선 이 버전의 역량이 어느 정도인가를 들여다보자. 관련해서 논문이 인터넷에 올라와 있어 적당히 참고해 본다. 이 버전을 소개 · 설명하는 전문가들도 주로 이 논문을 참고하기에 찾아보았다.
우선 버전 3.0/3.5는 ‘텍스트-한정 모델’(text-only model)인데, 버전 4.0은 ‘복합양상 모델’(multimodal model)이다. 이는 텍스트, 소리, 이미지, 심지어 동영상을 입력받아 복합적으로 처리하여 시청각 내용을 생성해 낼 수 있는 모델이라는 이야기다. 이 복합양상 모델의 AI가 발전함에 따라 그야말로 가까운 우리의 미래를 AI 또는 AI 로봇이 더 강하게 지배할 것이다. 우리의 생활 세계가 바로 기본적으로 이 같은 시청각 복합의 내용으로 되어 있기 때문이다.
2) ChatGPT 4.0의 역량
일단 상식 삼아 논문에 보고된 ChatGPT 4.0의 역량을 간략하게 정돈해 살펴보자.
① 미국 변호사 시험(Bar Exam) 상위 10%의 성적으로 합격했다.
② 생물학 올림피아드에서 상위 1%에 들었다.
③ 전문적이고 학술적인 57개의 주제에 관한 객관식 시험에서 86.4%(3.5버전, 70%) 정답률. 그리고 일상적인 사건에 관한 상식적인 추론에서 95.3%(3.5버전 85.5%) 등 → 이를 한국어로 번역해서 제시했을 때, 77% 정도의 정확도로 실현한다. 그 외 수없이 많은 언어로 번역해서 제시했고 엇비슷한 정확도를 보였다.
④ 그 외 미국 대학 학점을 선취할 수 있는 AP(advanced Placement) 시험에서 화학 70%, 통계학 82%, 생물학 83%, 물리학 70% 등의 점수를 받았고, SAT 수학에서 90% 점수를, 그리고 GRE(대학원 입학시험)의 수리 논증 80%, 언어 논증 99% 등의 점수를 받았다.
⑤ “신데렐라의 줄거리를 설명하라. 단, 반복되는 글자가 없어야 하고, 다음에 나올 단어는 알파벳 A부터 Z까지 순서대로 시작해야 한다.”라고 요청했더니, 다음의 문장을 거침없이 만들었다. (일부러 단어마다 대문자로 시작하게끔 바꾸었다. 대문자를 보면 A∼Z 순서로 단어를 골라 쓰는 것을 알 수 있다.)
“A Beautiful Cinderella, Dwelling Eagerly, Finally Gains Happiness; Inspiring Jealous Kin, Love Magically Nurtures Opulent Prince; Quietly Rescues, Slipper Triumphs, Uniting Very Wondrously, Xenial Youth Zealously.”
(번역) → “아름다운 신데렐라가 열심히 살다 마침내 행복을 얻는다. 사랑은 질투심 많은 친척을 고무시키면서 엄청나게 부유한 왕자를 마술처럼 키운다. 조용히 구출하고, 슬리퍼가 승리하고, 매우 놀랍게도 환대하는 젊은이들을 열심히 단결시킨다.”
⑥ 한꺼번에 50쪽에 달하는 문서를 순식간에 만들어 내는 서술 능력을 지녔다. 주어진 주제에 관해 어지간한 논문보다 훨씬 더 긴 문서를 깊이 있게 만들어 내는 능력을 지닌 것이다. 논문을 쓰는 학생과 지도 교수가 연구 주제를 주고 글을 쓰게 한 뒤, 그 내용을 함께 검토해 수정 · 보완해 논문을 제출하는 일이 성행할 것이다. 말하자면, 학술 영역에서 탁월한 지적인 능력을 발휘하는 기계 논문 대필 및 논문지도 기계 교수가 생긴 셈이다.
⑦ 3.5 버전에서 말썽이었던 정신을 잃은 것인 양 황당한 거짓으로 대답하는, 이른바 ‘환각’(hallucination) 현상이 현격히 줄어들었다. 이는 ChatGPT를 비아냥거리게끔 했던 핵심 문제를 제거했다는 것을 뜻한다. 어쩌면, 한편으로는 가짜 뉴스를 더욱 정교하게 만드는 데 악용될 수도 있으나, 다른 한편으로는 가짜 뉴스나 지식을 판별해 내는 데에 활용될 수 있겠다는 생각을 하게 한다.
⑧ 아래 그림을 주고서 여기에서 뭐가 웃기느냐? 차례대로 말해보라고 했더니,
(1) ”스마트폰 충전 포트에 VGA 연결기가 붙어있다. (2) “아이폰 충전케이블”을 담아야 할 포장 패키지에 VGA 연결기가 들어 있다.“ (3) ”VGA 연결기 단말에 작은 아이폰 충전기 연결기가 붙어 있다.“ (4) ”그러므로, 이 그림에서 웃기는 건(humor) 최근의 작은 스마트폰 충전 포트 속에 철 지난 큰 VGA 연결기가 꽂혀 있다는 황당함(absurdity)에서 비롯한다“라고 답했다.
이 능력은 대단히 중요하다. 일단은 인간 못지않게 상당히 고급스러운 형태의 유머가 어디에서 비롯하는가를 추론해서 그 근거를 제시한다는 데서 놀랍다. 그보다 중요한 것은 그림 이미지와 텍스트를 상황의 맥락에 맞게 연결해서 종합적으로 이해하는 능력을 보인다는 점이 워낙 중요하다. 우리 인간 역시 어떤 장면을 지각하면 알게 모르게 그에 상응하는 언어적인 표현들이 떠올라 결합하고, 언어적인 표현을 읽으면 그에 따라 이미지적인 상념이 함께 떠올라 결합하는데, 이를 통해 이른바 복합양상(multi-modality)의 방식으로 지적인 생활을 하기 때문이다. 이는 AI가 인간과 유사한 지성적인 체계로 성큼 다가와 있음을 시사한다.
더 나아가면, 그동안 특정한 영역, 예컨대 음악의 작곡 능력(예를 들어, 베토벤 제10번 교향곡 작곡), 그림이나 입체적인 개체를 섬세하게 만들어 내는 ‘메타버스’ 능력(예를 들어, 특정한 프로그램 사용법을 설명하는 꼭 진짜 인간 같은 아바타 창조), 음성/텍스트 변환 생성 능력, 자동번역 능력 등을 한꺼번에 결합해서 구사하는 단일 거대 AI 프로그램을 만들어 내는 것이다. 실제로 마이크로소프트 회사에서 ‘Copilot’이란 프로그램을 만들어 여기에 ChatGPT 4.0과 ‘마이크로소프트 오피스’ 등을 결합해서 출시했다고 한다.
말하자면, 뛰어난 학술, 행정, 사업경영, 친교 등에 관련해서 각종 실감 나는 프레젠테이션 잡무 능력을 두루 갖춘 비서를 가질 수 있게 된 셈이다. 간단히 말해, 하기에 복잡하고 귀찮은 일을 맡기면 어지간한 일은 인간이 직접 하는 것 보다 훨씬 더 고급스럽고 멋지게 만들어 낸다. 사용자가 결과물이 마음에 들지 않으면 수정 요구를 할 수 있고, 그에 따라 해당 내용을 새롭게 수정 · 보완하는 능력도 뛰어나다.
※ ChatGPT 4.0에 관한 설명과 충격에 관해 다음의 유튜브들을 보기 바란다. 시대에 뒤떨어지는 처지를 조금이라도 극복하는 데 도움이 될 것이다.
https://www.youtube.com/watch?v=WZD5ZWfE89I 정인성 작가
https://www.youtube.com/watch?v=eCKS_etvZyI 카이스트 김대식 교수
https://www.youtube.com/watch?v=wW67o7dbyFk 솔트룩스 이경일 대표
3) 특이점의 통과? ‘괴물’ AI의 출현?
1996년 IBM의 ‘딥 블루’가 세계 챔피언인 카스파로프를 체스 게임에서 이긴 건만 하더라도 충격적이었다. 이 사건으로 인해, 『컴퓨터는 무엇을 할 수 없는가』(1972/1992)라는 책을 통해 ”체스 게임에서 컴퓨터가 절대로 인간을 이길 수 없다.“라고 과감하게 선언했던 미국의 유명한 현상학을 기반으로 하는 철학자인 드레이퍼스(Hubert Dreyfus, 1929∼2017)는 컴퓨터과학계로부터 비웃음을 감당해야 했다. 그런 뒤 2016년 구글의 바둑 인공지능 ‘알파고’가 이세돌과의 대결에서 4승 1패의 성적을 거두었을 때, 전 세계인이 놀라움을 금치 못했다. 그 이후, 요즘 프로 바둑 해설가들은 항상 여러 바둑 인공지능의 지도를 참고한다. 그 외 2011년에 IBM의 인공지능 ‘왓슨’이 미국의 유명 퀴즈쇼인 Jeopardy!에 출연해 74연승을 거두며 250만 달러의 상금을 거머쥐면서 역대급 챔피언을 제치고 완승했고, 그 이후 암 진단 등의 인공지능으로 활용되면서 한국에서도 수많은 종합병원에서 도입하여 활용하기도 했다. 그뿐만 아니다. 특정 영역에서 뛰어난 실력을 발휘하여 아예 생활필수품이 되어버린 음성 인식 대화형 내비게이션은 물론이고, 실용화된 자율 주행 자동차의 인공지능, 쌍방향 대화형 스피커, 자동 회화 번역기 등은 상식이 되다시피 했다.
하지만, 이러한 AI는 인간보다 월등한 역량을 발휘하더라도 그 자체로 사유한다거나 수시로 변화하는 상황이나 맥락을 이해한다고는 생각되지 않았다. 비록 스스로 학습해서 계속 역량을 향상한다고 해도 뭔가 여전히 원천적으로 인간의 주도적인 개입이 없이는 역량을 발휘할 수 없는 것으로 여겨졌다. 말하자면, 흔히 ‘기계’라는 말에서 느낄 수 있는 수동성, 인과적인 결정, 맹목성, 타성 등의 성격을 제대로 벗어난 게 아니라는 우리의 인식을 넘어서지 못했다.
그런데, ChatGPT3.5 버전에 곧이어 4.0 버전이 나와 위에서 대략 열거한 역량을 발휘하게 되자 다들 충격에 빠지고 만 것이다. 이유가 무엇일까? 정확하게 짚어낼 수는 없지만, 그동안 인간만이, 즉 인간의 두뇌만이 할 수 있으리라 여겼던 ‘범용의 사유 능력’(general thinking capability)을 발휘한다고 인정할 수밖에 없는 사태가 벌어졌기 때문일 것이다. 사법적이거나 경영학적인 사유와 같은 실용적인 지식과 활용뿐만 아니라 수학 · 물리학 · 생물학 등의 순수자연과학과 나아가 문학 · 역사 · 심리학 · 미술사 등의 인문 예술적 사유 영역마저 대학생 내지는 대학원생 이상의 높은 지적인 능력을 동시에 이른바 ‘범용적으로’ 발휘한다는 게 입증되고 만 것이다. 게다가 소프트웨어 프로그램의 코딩은 물론이고 시, 소설, 시나리오, 디자인 등의 창작에도 동시에 실용성이 상당한 수준으로 능력을 발휘한다. 게다가 위 유머 관련의 질문과 대답에서 알 수 있듯이, 맥락의 가변성이 높은 일상적인 대화에까지 끼어들 수 있다는 암시를 주고 있다. 요컨대, 드디어 복합양상의 범용 인공지능(AGI, artificial general intelligence)을 현실화했다고 여기지 않을 수 없는 일종의 ‘괴물’이 등장한 것이다.
사실, 이러한 ‘괴물’뿐만 아니라 그 이상의 상상을 불허할 정도의 ‘거대 괴물’이 출현하리라는 예고는 수도 없이 제시되었다. 각종 SF 영화나 소설 등은 물론이고, 전문 과학기술자들 사이에서 마치 모르면 시대착오적인 인물에 불과할 뿐이라는 식의 장밋빛 전망과 치명적인 경고성 발언이 있었다. 그중 가장 선풍적인 관심을 끌어모은 것은 2000년 초에 「미래에 왜 우리는 쓸모없는 존재가 될 것인가?」 하는 글을 통해, 2030년대쯤이면 로봇들이 모여 이 열등한 인간들을 어떻게 처리해야 하는가, 하는 회의를 진행하게 될지도 모른다는 빌 조이의 음울한 경고였다.
그런 뒤, 빌 조이와 함께 작업하기도 했던 커즈와일(Ray Kurzweil, 1948∼ )이 2005년에 『특이점이 온다The Singularity is Near』(김명남 · 장시형 옮김, 김영사, 2007)라는, 국역본으로 840쪽에 달하는 엄청난 불량의 책을 출간했다. 여기에서 저 유명한 ‘특이점’(singularity) 개념이 제시되었다. 이는 컴퓨터 AI의 능력이 인간의 능력을 넘어서기 시작하는 시점을 지시한다. 초인간적인 AI가 등장하면 그 위력이 초고도의 컴퓨터 기술을 기반으로 한 여러 다른 첨단의 고도 과학 기술과 결합함으로써 상상할 수 없는 일들이 벌어질 것이고, 따라서 특이점의 도래는 인류의 미래는 물론이고 세계 자체의 존재 방식을 일변해버릴 것이라고 예상한다. 말하자면, 인권이 기계에 의해 근본적으로 추락하는 ‘존재론적인 불상사’가 벌어지는 것이다.
분자 나노로봇은 물론이고 온갖 화학물질을 물리학적으로 만들어 내는 나노기술; 뇌를 비롯한 온갖 형태의 생물학적-유기체의 기관을 만들어 내는 유전공학; 결국에는 실제 지각의 현실과 꾸며낸 가상의 현실 사이의 구별을 무의미하게 만들어버릴 가상현실 기술; 인간의 실제 신경과 뇌에 각종 컴퓨터 칩을 삽입해 결합 · 호환되도록 하여 유기체와 기계의 구별을 무의미하게 만들어버릴 사이보그 기술; 주변의 뭇 사물들이 정보를 생성 · 전달함으로써 전반적인 연결망을 통해 기능하도록 하는 사물 인터넷 기술; 그리고 무엇보다 인간과 함께 당당하게 시민권을 요구하면서 길거리를 활보하게 될 각종 개체 구현의 로봇을 만들어 내는 로봇공학 기술; 그 와중에 핵융합 발전에 의한 초고도 용량의 발전 기술 등이 머지않은 미래를 향해 경쟁적으로 질주하고 있다.
사이보그 기술에 관련한 담론 중 한 가지만 예로 들어보자. 2016년 로빈 핸슨(Robin Hanson, 1959∼ )은 『뇌 복제와 인공지능 시대The Age of EM: Work, Love and Life When Robots rule the Earth』(최순덕 · 최종적 옮김, 씨아이알, 2019)라는 책을 발간했다. 핸슨은 이 책에서 ”전뇌(全腦) 에뮬레이션(whole brain emulation)의 문제는 그 가능성의 유무가 문제가 아니라 언제 이루어질 것인지의 문제인 듯하다“라고(67쪽) 말한다. 그는 컴퓨터 기계와 인간 뇌 사이에, 하나의 컴퓨터 시스템이 다른 컴퓨터 시스템을 모방 · 복제하여 똑같이 따라서 행동하듯이, 컴퓨터-로봇과 인간 뇌 사이에 모방 · 복제가 가능함을 강력하게 주장한다. 그 결과를 구체적으로 묘사하기도 한다: ”제대로 작동하는 에뮬레이션은 자신이, 스캔 된 원본 뇌 소유자와 똑같은 방식으로 대화, 사고, 사고방식, 감정, 카리스마, 정신적 능력을 발휘할 수 있다. 또한 체리파이의 맛을 느끼고, 힘든 운동이나 성적 쾌감과 같은 유사 경험을 에뮬레이션하는 것도 가능할 것이다. 에뮬레이션은 마치 우리와 똑같이 자연스럽게 에뮬레이션 자신이 의식과 자유의지를 가지고 있다고 스스로 가정하려 들 것이다.“(69쪽)
외삽법(extrapolation)이라는 사유 기법이 있다. 이는 원래의 사실에 대한 관찰 범위를 넘어 다른 변수들과의 관계를 기반으로 그 이상의 값을 얻는 방법이다. 위 ChatGPT 4.0이 발휘한 역량을 외삽법에 따라 적용하게 되면, 이제 방금 열거한 여러 첨단 고도 과학 기술을 발전시키는 데에 인간보다 AI가 더 큰 역할을 담당하게 될 것이고, 그에 따라 그동안의 예상을 훨씬 상회하는 속도로 기술이 발전하게 될 것이다. 이에 다가드는 불안의 핵심은 ‘인간 존재의 몰락’ 내지는 그와 크게 다르지 않은 ‘인간 존재 자체의 대변형’이다.
쉽게 알 수 있듯이, 분명 급진적인 도약이 있겠지만 특이점이 순식간에 확 들이닥치는 건 아니다. 하지만 그 확실한 시작 단계가 확인될 것인데, 이번 ChatGPT 4.0의 출현이 그 시작 단계라 해야 하지 않을까? 아마도 그럴 것 같다. ChatGPT만 준비된 범용 AI가 아니다. 마이크로소프트 외에 구글, 페이스북, 우리나라의 네이버에서도 범용 AI 시스템을 내놓고 있다. 나라마다, 특히 중국의 경우 아마도 강력한 범용 AI 체계를 준비하고 있다. 이번 ChatGPT 4.0의 출시를 신호로 범용 AI 들이 쇄도하여 전 세계를 소용돌이로 몰아넣을 것이다.
누군가는 새로운 매체가 등장할 때마다 본래 ‘충격적이니’ 어쩌니 하면서 요동치게 마련이고, 그러다가 적응 과정을 거쳐 안정적인 상태로 습관화되기 마련이니, 이번 ChatGPT 4.0을 비롯한 범용 AI도 마찬가지일 것이라고 낙관적인 견해를 펼칠 것이다. 1427년 마사초가 완벽하게 원근법을 활용해 그린 거대한 벽화 <성 삼위일체>(세로 6.67미터, 가로 3.17미터)를 덮었던 천을 벗겼을 때, 사람들은 아니 언제 이렇게 벽에 조각을 했단 말인가? 하고서 놀라운 반응을 보이면서 놀라 기겁하였다고 전해진다. 1839년 처음 다게르의 사진술 전시회가 열렸을 때, 사진이 화가보다 훨씬 더 세밀하게 사건의 장면을 묘사할 수 있음이 판명되다니 어찌 이런 일이? 하면서 구경꾼 중 누군가가 ”이제 회화는 죽었다“라고 했다. 하지만, 사진이 표현할 수 없는 그림을 모색해 인상파 회화가 탄생하고 그래서 오히려 현대 미술이 화려하게 만개했다. 그런가 하면, 1895년 12월 뤼미에르 형제가 르 그랑 카페에서 <라 시오타 역에서의 열차의 도착>이라는 50초짜리 짧은 영화를 처음 틀었을 때, 앉아있던 사람들이 달려오는 기차에 치일까 봐 일어나 도망쳤다고 한다. 그뿐만이 아니다. 전등이 환하게 켜지고, 다양한 형태와 기능의 전기 모터가 돌아가고, 고속 엘리베이터가 만들어지고, X-레이 촬영기, 라디오, 텔레비전, 원자력 발전소, 인공위성, 컴퓨터, 인터넷, fMRI 촬영술, 스마트폰, 원자력 현미경, 제임스-웹 망원경, 자율 주행 자동차 등 온갖 놀라운 기술들이 우리의 삶 깊숙이 파고들었지만, 아무런 문제도 없는 양 결국 습관화된다.
ChatGPT AI가 출현한 것에 대해서도 그럴 수 있을까? 아마 그럴 거야. 물론 특별한 점이 없는 건 아니지만, 우리 인간들이 슬기롭게 잘 대처할 것이고, 그러기 위해 전 세계가 발 벗고 나서서 관련한 윤리 강령을 제시하고 강력한 법을 만들어 부작용을 방지하게 될 것이니 그다지 걱정할 일은 아니야, 하는 식의 반응을 보일 수도 있다.
하지만, 과연 그런 방향으로 온 인류가 ‘인간 존재의 몰락’을 막아내는 일에 성공할 수 있을까? 하는 의구심을 떨쳐버릴 수 없다. 핵폭탄 기술이 핵발전 기술로 전환되는 것과 같은 방향으로 과연 나아갈 수 있을까? 『로봇의 부상, 인공지능의 진화와 미래의 실직 위협Rise of the Robots: Technology and the Threat of a Jobless Future, 2015』(이창희 옮김, 세종서적, 2016)을 쓴 유명한 미래학자인 마틴 포드(Martin Ford)는 ”실리콘밸리에서는 사람들이 ‘와해성 기술’(disruptive technology)이라는 말을 아무렇지도 않게 주고받는다. 몇몇 산업을 완벽히 파괴하거나 특정 분야를 교란할 능력이 기술 속에 숨어 있음을 의심하는 사람은 아무도 없다.”라고(21쪽) 말한다. 그러면서 “기술 발전이 사회 시스템 전체를 와해시킨 뒤에도 인류가 지속해서 번영을 누리려면 근본적으로 모든 것을 재편성하는 상황까지 가야 하는가?”라는(같은 곳) 물음을 던진다. 2014년에 스티븐 호킹 박사가 ”진정으로 사고할 수 있는 기계를 발명한다면 인류 역사상 가장 큰 사건이 될 것“이라 경고한 점을 상기시키면서, 그는 ‘특이점’에 대해 ”지능 폭발“이란 개념을 내놓는다. 지능 폭발의 결과, 어떤 인간보다도 수백만 배 더 현명한 기계가 등장할 수도 있다는 것이다. (356쪽 참조)
암튼, 스티븐 호킹의 경고가 있은 지 채 10년이 지나지 않아 ChatGPT의 등장을 계기로 과연 ”인류 역사상 가장 큰 사건“이 일어나고 있는지 그 여부를 판가름해야 할 상황에 직면한 것만은 분명해 보인다.
- 범용 AI의 기본 원리
그렇다면, 우리 인류는 어떻게 해서 이러한 전대미문의 기술을 착착 준비해 왔을까? 철학 공부도 겨우 할까 말까 한 필자로서는 1950년대부터 지금까지 긴 세월에 걸쳐 무수히 많은 천재적 인물들이 달려들어 실패와 성공을 거듭하다가 급기야 ChatGPT 4.0에 이르기까지 달려온 그 전문적인 원리를 제대로 알 길은 없다. 수박 겉핥기 정도로 이해한 두 가지만 상식 삼아 소개하고자 한다.
1) 심층 기계학습
예컨대 기계가 언어를 ‘이해하고’ 사람과 자연스럽게 대화하기 위해서는 어떤 방식으로 움직이도록 해야 할까?
이에 관한 핵심 아이디어는 자연스럽게 언어를 사용하는 인간 두뇌의 구조와 기능 발휘의 방식을 따르면 되지 않겠는가, 하는 것이다. 이를 염두에 두고 만든 프로그램 작성 방식을 인공 신경망(ANN, artificial neural network)이라고 한다. 다 알다시피, 인간 두뇌에는 1,000억 개에 이르는 뉴런들이 어마어마하게 복잡한 연결망을 구성해 작동한다. 그 연결망을 이루는 기본은 시냅스 연결이다. 하나의 뉴런은 약 5,000개의 시냅스 연결 지점들을 지니고 있다. 그러니까 하나의 뉴런에 정보가 전달되면 원칙적으로 최대한 5,000개의 다른 뉴런들에 그 정보를 한꺼번에 전달할 수 있다. 인공 신경망은 이를 흉내 내어 만든 것이다.
언어 처리를 원만하게 할 수 있는 프로그램을 만들고자 한 1980년대에는 프로그램에 언어의 문법들을 미리 집어넣고 그 문법들을 기본 규칙으로 해서 외부에서 주어진 언어 데이터를 기반으로 언어를 생성하게끔 하려 했다. 이를 ‘규칙 기반 인공지능’(rules based AI)이라 부른다. 이것은 현대 최고의 언어학자인 촘스키(Noam Chomsky, 1928∼ )가 정신-뇌(mind-brain) 속에 언어 습득을 위한 보편문법 장치를 타고난다는 주장에 따른 것이었다. 실패였다. 타고난 보편문법 장치를 제대로 알 수도 없거니와 문법의 규칙들이 낱말들이 쓰이는 맥락에 따라 워낙 많았기 때문이다. 그래서 이른바 ‘인공지능의 겨울’이 들이닥쳤다.
그러다가 2010년에 들어서면서 위에서 말한 뇌를 모방한 ‘심층학습 기반 인공지능’(deep learning based AI)을 개발하게 된다. 그러면서 아이들이 말을 배울 때 문법부터 배운 뒤에 말을 배우는 것이 아니라는 실제의 현상에 주목하게 된다. 그리하여 마치 ‘알파고 제로’가 ‘알파고’와는 달리 바둑의 규칙을 미리 인간에게 배우지 않고 수많은 기보들을 검토하여 스스로 바둑의 규칙을 알아내고 그에 따라 바둑을 둠으로써 ‘알파고’에게 백전백승한 것처럼, 언어학습 프로그램이 어마어마한 언어 데이터들을 검토하여 저 스스로 언어의 문법을 맥락에 따라 찾아내어 적용할 수 있게 되었다.
그럴 수 있었던 것은 첫째, www(world wide web) 인터넷의 개발로 1990년부터 활성화되기 시작해 거의 20년에 걸쳐 축적된 무진장한 빅 데이터를 활용할 수 있었고, 둘째, NVIDIA 회사에서 GPU 병렬 프로세스를 개발함으로써 선형적인 방식으로 순차적으로 하는 계산이 아니라 엄청난 양의 동시적인 병렬 계산(convolution)을 할 수 있게 되었고, 셋째, 반도체 기술이 크게 향상됨으로써 1초에 수경( ) 번씩 초고속도로 연산할 수 있는 슈퍼컴퓨터를 만들었기 때문이다.
우선 인공 신경망의 간단한 원리를 보기로 하자. 인공 신경망은 입력층(input layer)→은닉층(hidden layer)→출력층(output layer)으로 구성된다. 그리고 각 층(layer)은 수없이 많은 인공 뉴런인 노드(node)로 구성된다. 그 구성을 아주 간단하게 도해하면 다음과 같다.
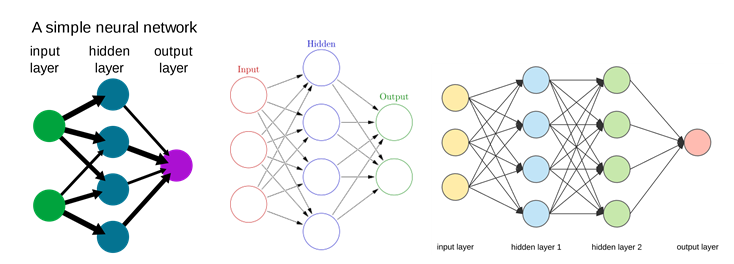
그림 1>과 그림 2>는 중간의 은닉층이 하나이고, 그림 3>은 은닉층이 두 개다. 그리고 하나의 은닉층은 네 개의 인공 뉴런으로 되어 있다. 하지만, 실제 인공 신경망 심층학습 프로그램은 은닉층이 어마어마하게 많을뿐더러 하나의 은닉층을 구성하는 인공 뉴런의 수도 엄청나다.
그림 3>을 보면 입력층을 구성하는 세 개의 뉴런마다 은닉층 1을 구성하는 네 개의 뉴런 각각에 모두 정보를 전달한다. 그러니까, 은닉층의 각 뉴런은 입력층의 세 군데에서 정보를 받는다. 그리하여 각 뉴런은 그렇게 세 군데에서 온 정보를 나름으로 종합한다. 그리고 은닉층 1을 구성하는 네 개의 뉴런마다 은닉층 2를 구성하는 네 개의 인공 뉴런 각각에 자신이 종합한 정보를 보낸다. 그러니까 은닉층 2의 각 뉴런은 은닉층 1에서 네 개의 정보를 받아 종합한다. 그리고 마지막 출력층의 뉴런에 그 모든 정보가 전달된다. 간단하게 계산하면 마지막 출력층에서 처리되는 정보는 3x4x4=48개의 정보가 하나로 종합된 것이다.
그림 3>에서 은닉층은 수학으로 치면 두 개의 함수로 구성되어 있고, 출력층은 두 개 함수의 값이 복합적으로 결합해서 나온 최종적인 값이라 할 수 있다. 이때 은닉층의 함수에는 매개 변수들이 복잡한 방식으로 작동하는데, 여기에서는 각 은닉층의 뉴런이 매개변수의 역할을 한다고 할 수 있다. (정확한 이해는 아니다. 이보다 훨씬 복잡할 것이다. 함수의 종류도 많거니와 매개변수의 종류도 많기 때문이다) 매개변수는 함숫값을 결정하는 데 핵심 역할을 한다.
여기에서 중요한 것은 각 층의 뉴런들을 연결하는 링크의 선들이다. 이 선은 주어지는 정보 자극의 강도를 나타낸다. 그림 1>을 보면 링크의 선의 굵기가 다르게 표현되어 있는데, 이는 입력층의 뉴런들 각각에서 은닉층의 뉴런에 주어지는 정보 자극의 정도가 다름을 나타낸다. 정보 자극의 강도가 약하면 그 자극을 받은 뉴런이 전혀 작동하지 않을 수 있다. 즉, 주어지는 자극의 강도가 어느 정도 이상이라야만 자극받은 뉴런이 반응하는 것이다. 이를 일컬어 해당 뉴런의 역치(threshold)라고 한다. 매개변수의 역할을 하는 뉴런마다 역치가 다를 수 있고, 그에 따라 최종적으로 출력되는 값이 다르게 조정되어 출력된다. 이는 인간 두뇌의 뉴런이 정보를 처리 · 전달하는 기본 원리다. 이를 그대로 본떠 만든 것이 인공 뉴런이다.
만약 ”아빠는 엄마를 사랑한다“라는 문장이 있다고 해보자. 이를 그림 3>에 적용해 보자. 입력층의 세 뉴런 각각에 위에서부터 ‘아빠’, ‘엄마’, ‘사랑’이라는 내용이 할당되고, 은닉층 1의 네 뉴런 각각에 위에서부터 ‘…는’, ‘…를’, ‘…한다’, ‘…이다’라는 내용이 할당된다고 해 보자. ”아빠를 사랑은 사랑를“이라는 엉터리 문장이 나올 수도 있다. 그런데 이와 동일한 문장, 예를 들어 ”영철이는 개를 좋아한다“와 같은 문장을 10만 개 넣어 훈련한 뒤, 마지막 출력층에 ”아빠는 엄마를 사랑한다“라는 정상적인 문장이 나오도록 하려면 어떻게 해야 할까?
‘…는’, ‘…를’, ‘…한다’, ‘…이다’ 등은 10만 번 가까이 반복될 것이다. 이때 ‘…는’이라는 매개 뉴런이 작동하기 위해서는, 이 뉴런이 사랑하다, 일하다, 쓰다, 뛰다 등의 동사가 주는 자극에 쉽게 반응하지 않는다. 말하자면, 이에 대해서는 역치가 높아 정보 전달이 안 된다. 그 대신 명사가 주는 자극에 더 쉽게 반응해서, 말하자면 이에 대해서는 역치가 낮게 반응해서 작동해야 한다. 이를 위해서는 은닉층의 뉴런마다 상황의 맥락에 따라 역치를 조정할 수 있어야 한다. 마지막 출력 값이 잘못되었을 때마다, 잘못되었음을 계속 되돌려 알려주면 이러한 역치를 조정해 나가는 과정을 계속 반복할 수 있도록 프로그램을 짜야 한다. 이러한 알고리듬을 ‘역전파 알고리듬’(backpropagation)이라고 한다. 이 알고리듬을 통해 역치 조정의 과정을 많이 거치면 거칠수록 점점 더 정확한 출력 값, 즉 자연스럽고 정상적인 문장을 만들어 낼 것이다. 이러한 역전파 알고리듬을 통해 ‘강화 학습’(reinforcement learning)이 이루어진다.
이때 중요하게 작동하는 기능이 ‘주의 집중’(attention)이다. 즉, 입력된 데이터의 낱말들이나 조사 또는 전치사 등에서 무시해야 할 것과 중시해야만 할 것을 점점 더 정확하게 식별할 수 있도록 하는 알고리듬을 함께 집어넣는 것이다.
이는 결국 인류가 만들어 낸 온갖 문장들에서 특정한 단어들끼리 결합할 확률, 그리고 특정한 구절이나 문장들끼리 연결될 확률을 계산해 나가는 과정이고, 그 확률의 현실 적합성의 정도를 높여 나가는 것이다. 최종적으로 어마어마한 언어 사용 예의 전체적인 확률 분포도를 만들어 활용하게 되는 것이다.
무한에 가까운 어마어마한 양의 데이터를 /sec의 속도로 제공하고, 이러한 역전파 수정 · 보완 작업을 역시 /sec의 속도로 반복한다면, 그리고 이러한 작업을 어마어마한 장소들에서 동시다발적으로 병렬적으로 수행한다면, 사전 훈련을 계속할수록(pre-training) 저 스스로 더 깊이 있게 변형해나가는(transforming) 학습을 해나가는 것이다. 그리하여 외부에서 주어진 자극, 예컨대 대화자가 ”철학 공부를 잘하려면 어떻게 해야 하는가? “ 하고서 질문을 했을 때, ”철학 공부에는 지름길이 특별히 없습니다. “라는 대답을 생성해(generation) 출력하는 것이다.
2) 적대적 생성의 연결망
한편에는 입력된 내용을 처리함으로써 뭔가를 만들어 내는 ‘생성 장치’(Generators)가 있고, 다른 한편에는 생성 장치의 결과를 최대한 잘못되었다고 판별해 내는 ‘식별 장치’(Discriminators)가 있어 ‘생성 장치’는 ‘식별 장치’의 힘을 무너뜨리고자 하고, ‘식별 장치’는 ‘생성 장치’의 힘을 무너뜨리고자 하는 경쟁을 붙이는 이른바 ‘적대적 생성의 연결망’(GAN, generative adversarial network)의 알고리듬을 만들어 쓰는 것이다. 정확하게는 알 수 없지만, 이 연결망 알고리듬이 바로 앞에서 말한 ‘역전파’ 알고리듬이 아닌가 짐작한다.
- AI 기계의 욕망과 의식
1) 컴퓨터의 기본 구조와 기능
제아무리 발달한 AI라 할지라도 결국에는 반도체 기반의 하드웨어가 작동하는 것이다. 그 작동을 명령하는 것이 AI 알고리듬들의 복합인 ChatGPT 4.0과 같은 프로그램이다. 반도체의 작동은 잘 알다시피 3〜5V 정도의 전류를 통하거나(ON) 차단하거나(OFF) 함으로써 이루어진다. 이를 수학적으로 흔히 1과 0이라 말하면서, 정보의 값을 32비트니 64비트니 하면서 2진법으로, 즉 디지털 방식으로 표현하는 것이다. 말하자면, 낱말이건 문장이건 문서건, 그리고 이미지건 이미지들이 변화하는 동작이건 간에 입력층을 통해 그것들에 의한 자극을 받을 때, 그 자극은 결국 극미한 트랜지스터에 3〜5V의 전류를 통하거나 차단함으로써 수로 표기되는 정보가 된다. 그리고 이러한 정보를 처리하는 컴퓨터 언어로 된 알고리듬들 역시 결국은 수로 표기된다. 그리고 그 수들은 결국 어마어마하게 거대한 크기의 2진법의 수들로 환원되어 표기되고, 그 2진법의 수들은 무한하다고 해도 과언이 아닐 정도로 많은 트랜지스터로 된 칩들이 결합한 하드웨어 장치를 통해 전기적인 방식으로 처리되는 것이다.
발광체를 통한 빛이나 레이저 빔 등을 통해 자극이 주어지더라도, 결국 그 자극들은 전기적인 방식으로 입력되어 전기적으로 처리된다. 빅 데이터도 전기적인 방식으로 저장되고, 출력될 때도 전기적인 방식으로 출력된다. 요컨대 전반적으로 환원해서 말하면 AI 로봇은 오로지 전기적인 자극에서 시작해서 전기적인 반응을 나타낼 뿐이다. 그 중간 과정에서, 음성 카드, 그래픽 카드, 동영상 카드, 가상현실 카드, 또는 인공위성과 광섬유와 증폭기 등의 하드웨어 등을 거쳐 아날로그적인 형태로 변환하는 것이다.
2) 컴퓨터-기계 뇌는 감각 능력이 없다.
이 과정에서 컴퓨터-기계 뇌(이하 AI 로봇이라 지칭)가 인간의 두뇌와 전격적으로 다른 것은, 실제로 우리가 보고 듣고 만지고 냄새 맡고 맛보고 할 때 의식의 대상으로 얻어 향유 하는 감각적인 질을 갖지 못한다는 사실이다. 우리 인간이 두뇌를 중심으로 한 신경 작용에서 전기화학적인 과정을 거치는 건 AI 로봇과 같다. 그러나, 우리 두뇌는 그 처리 과정에서 감각적인 질을 산출해 내고 아울러 지각과 사유 및 상상 등의 의식을 산출해 내고, 그에 따른 감정과 의지 등을 발휘한다.
그런데도 우리는 이제 특이점 운운할 정도로 AI 로봇이 성큼 다가온 것 같은 낌새를 차리는 가운데, 이 AI 로봇이 우리처럼 색을 보고 소리를 듣고 냄새 맡고 생각하고 말하고 행동한다고 여긴다. 과연 그런가? 방금 말한 바에 따르면, 전혀 그렇지 않다. 하지만, 그저 전혀 그렇지 않다고 말할 수는 없다. 그건 비록 AI 로봇이 순전히 전기적인 방식으로 움직인다고 하더라도, 그 결과를 대하는 나에게는 전기적인 방식의 움직임은 보이지 않고 마치 우리가 다른 사람을 대할 때처럼 아날로그적인 방식으로 움직이는 것만 확인하면서 내가 그에 따른 감각적인 질을 추정 · 투사하기 때문이다.
이는 다른 사람에 대해서도 마찬가지다. 우리는 다른 사람의 의식도 직접 경험할 수 없고, 그 사람이 느끼고 대하는 감각적인 질을 직접 경험할 수 없다. 오로지 그 사람이 나타내면서 나에게 주어지는 아날로그적인 내용들을 확인하면서 그에 따른 감각적인 질을 다른 그 누구도 아닌 내가 파악할 뿐이다.
그러니까 우리가 AI 로봇을 대하는 것이건 다른 사람을 대하는 것이건 외부에서 그 내용을 파악할 뿐이기 때문에 둘이 겉으로 내보이는 내용은 똑같다. 말하자면, 우리가 다른 사람의 말과 표정과 행동을 보고서 그가 의식을 지녔고, 욕망을 지녔고, 의지를 발휘하면서 목적을 실현하고자 한다고 하듯이, AI 로봇에 대해서도 그렇게 말할 수밖에 없는 지경에 이르게 되는 것이다. 그러나, 다른 사람 역시 나와 마찬가지로 그 나름으로 감각적인 질을 향유 한다는 사실, 그리고 AI 로봇은 원리상 다른 사람과 달리 결코 감각적인 질을 향유 할 수 없다는 사실 만큼은 확실하다. 과연 이러한 차이가 실제 삶에 있어서 어느 정도로 의미가 있을지는 가까운 미래에 일어날 실제를 통해 확인해야 하겠지만, 아마도 쉽게 무시할 수 없을 것이다. 이 차이에서 기계를 상대로 한 인권에 관련한 여러 문제를 창의적으로 생각해서 그 해결 방안들을 모색하는 것이 가능하리라 예상해 본다.
(보충)
ChatGPT 3.5에서는 대화에서 어떤 질문이 주어질 때, 그 질문에 어떤 답을 최종 결과를 생성해 제공할 것인가를 결정하는 데 1,750억 개의 매개변수를 활용한다고 발표되었다. 이는 가장 적절한 답을 제시하는 데에 그만큼 관련한 많은 요건을 여러모로 고려한다는 뜻이다. ChatGPT 4.0에서는 매개변수의 수가 1조 개 이상 될 거라는 이야기도 있었지만, OpenAI에서 숨기고 짐짓 발표하지 않는다고 한다.
매개변수의 수는 워낙 중요하다. 매개변수는 낱말이건 구절이건 문장이건, 또는 각종 이미지건 간에 그것들의 다양한 쓰임새의 맥락에서 패턴을 이루는 특성들을 찾아내어 그것들이 구체적인 개별 대상으로서 주어질 때 그 본성을 파악하고 식별하는 데 쓰이는 것이기 때문이다. 그러니까 매개변수의 수가 많으면 많을수록 세상에 존재하는 온갖 언어의 온갖 종류의 문서들에 따른 낱말과 문장들을 더 섬세하고 정확하게 파악하여 식별할 수 있고, 또 세상에 존재하는 온갖 동식물과 사물들을 그 각종 특성과 그것들이 나타나는 패턴들에 따라 더 섬세하고 정확하게 파악하여 식별할 수 있다. 예를 들어, 우리 인간 얼굴의 표현 방식은 엄청 다양하다. 감정에 따라 얼굴을 구성하는 눈빛, 눈매, 입 모양, 코의 실룩거림, 광대뼈 주변의 피부 근육 등의 형태가 전반적으로 달라진다. 감정에 따른 그 모든 특성과 패턴을 일일이 파악하여 실제 얼굴에 적용하게 되면, 그 얼굴의 주인공이 어떤 감정 상태에 놓여있는가를 파악하여 식별할 수 있을 것인데, 여기에 필요한 매개변수가 과연 몇 개이겠는가?
앞서 말한 것처럼, 매개변수를 담당하는 인공 뉴런은 각기 나름의 역치를 지니고서 작동하며 그 역치는 특히 역전파 알고리듬에 의해 조정 가능하다고 했다. 이는 ‘주의 집중’과 연결된다. 외부에서 주어지는 입력의 자극들에서 어떤 것들을 어느 정도로 중시/무시할 것인가를 결정하여 각각의 강도(영향 값)를 자동으로 조절한다는 것이다. 그리고 그에 따라 사전 훈련된 어마어마한 학습 내용을 초고도의 속도로 검색하여 가장 적합한 답을 순식간에 제시한다는 것이다.
예를 들어, “철학적 사유를 하는 데 가장 중요한 점이 무엇인가?” 하는 질문을 했을 때, ‘이성’, ‘감각’, ‘상상’, ‘논리’, ‘정합성’, ‘모순’, ‘사물’ 등의 낱말이 쓰이는 맥락이나 패턴에 대해서는 주의 집중(attention)의 강도를 높이는 대신, ‘매매’, ‘타협’, ‘놀이’, ‘도시’ 등의 낱말이 쓰이는 맥락이나 패턴에 대서는 주의의 강도를 낮추어야 할 것이다. 이러한 맥락이나 패턴을 담당하는 것이 매개변수다.
그 외, 어떤 이미지를 보고 개인지 고양이인지를 구별하려면, 눈동자가 둥근지 세로인지(일종의 패턴으로서 매개변수)를 주의하는 강도가 높은 데 반해, 다리가 네 개인가(역시 일종의 패턴으로서의 매개변수)를 주의하는 강도는 제로일 정도로 낮아야 할 것이다. 개개 대상들을 그 종류별로 구별하기 위해서는 (1) 하나의 대상이 갖는 특성들을 다른 대상이 갖는 특성들과 비교해 그 동일성과 차이를 찾아내고, (2) 그 대상들이 정지했을 때나 움직일 때 변화하면서 나타내는 특성들의 패턴들이 갖는 동일성과 차이를 찾아내고, (3) 그것들의 동일성과 차이들을 통합해서 최종적으로 그 정체를 결과로 제시해야 한다. 이때 특성들과 패턴들을 담당하는 게 매개변수로 작동하는 은닉층의 인공 뉴런이다.
1. 이 논문은 OpenAI에서 <GPT-4 Technical Report>란 제목으로 작성해 보고문 형태로 https://arxiv.org/abs/2303.08774에 올라와 있다.
2. ‘매개변수’(parameter): 원인과 결과의 인과 관계에서 원인이 독립 변수라면, 결과는 종속 변수다. 그리고 이를 매개하는 제3의 변수가 매개변수다. 그러니까 매개변수는 독립 변수에 대해서는 결과로 나타나지만, 종속 변수에 대해서는 원인으로 작동한다. 매개변수가 많을수록 결과를 생성해내는 데에 더 많은 경우를 고려하기 때문에, 원하는 바 더 정확한 결과를 만들어낼 수 있다. 매개변수가 작동하는 정도, 달리 말해 그 강도는 경우에 맞춰 얼마든지 달라질 수 있다. 예를 들어, 내일 비가 올 확률과 그 강수량이 어느 정도 될 것인가를 예측하고자 할 때, 오늘 상공에 모인 비구름의 두께와 너비는 중요한 매개변수가 된다. 그리고 바람이 어느 정도로 강하게 불고 있는가도 중요한 매개변수다. 한편 오늘 기온이나 습도가 어느 정도인가도 충분히 중요한 매개변수가 될 수 있을 것이다. 그런데 이 매개변수 들이 내일 비가 어느 정도로 올 것인가를 결정하는 데 각각 어느 정도로 영향을 미치는가는, 예를 들어 계절에 따라 다를 수 있다. 경우에 따라 이러한 각각의 매개변수의 영향의 값을 어느 정도로 매기는가에 따라 최종적인 결과의 값은 크게 달라질 것이다.
